
Transformer TTS
Published:
1. Introduction
In this post, I’ll highlight Transformer TTS, a model proposed by Li et al. (2019) that brought the Transformer architecture to neural text-to-speech (Speech Synthesis). It improves upon RNN-based systems like Tacotron 2 by removing recurrence, enabling parallel computation, and enhancing the modeling of long-range dependencies is key to generating natural prosody in speech.
You can listen to audio samples from the official authors at:
https://neuraltts.github.io/transformertts/
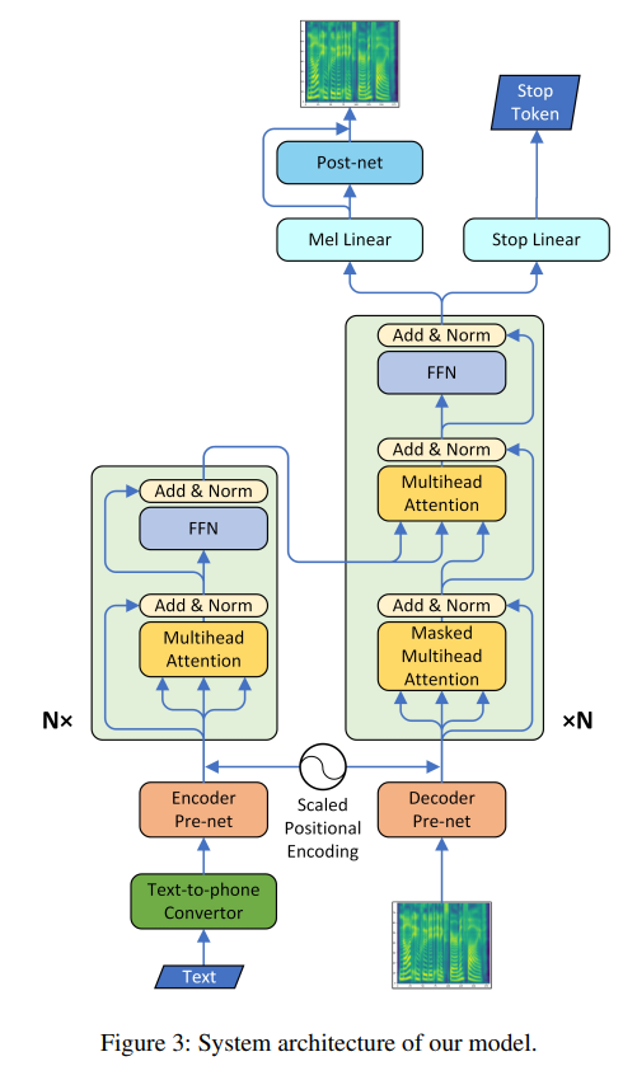
Transformer TTS replaces RNNs with self-attention across both encoder and decoder, enabling parallel training and long-range context modeling.
2. Front-End Processing
2.1 Text-to-Phoneme Converter
Transformer TTS begins by converting raw text into phoneme sequences using a rule-based system. This reduces mispronunciations, especially for rare or irregular words, and provides a more consistent input for the encoder.
3. Input Representation Modules
3.1 Encoder Pre-Net (same as Tacotron 2)
The encoder pre-net in Transformer TTS transforms phoneme tokens into contextual embeddings optimized for attention-based processing.
It consists of:
- Embedding layer (512-dim)
- 3-layer 1D CNN: Captures short- and long-term phoneme context
- BatchNorm, ReLU, Dropout after each CNN layer
- Linear projection: Ensures compatibility with positional encodings
Why the Linear Projection Matters
- In the original Transformer, positional encodings are zero-centered sinusoidal signals added directly to token embeddings.
- However, in Transformer TTS, the encoder pre-net ends with ReLU activations, making outputs strictly non-negative.
- This leads to a representation mismatch when adding zero-centered positional encodings to non-zero-centered CNN outputs.
Problem
Adding zero-centered PE to non-zero-centered CNN outputs causes representation drift and harms learning dynamics.
Solution
\[x_i = \text{Linear}(\text{ReLU}(\text{Conv}(embedding_i))) + \alpha \cdot PE(i)\]A linear projection layer is added after the final ReLU to re-center the embeddings before adding PE:
This design tweak helps make sure that:
- Better numerical compatibility with sinusoidal encodings
- Improved training stability
- Higher quality spectrogram generation
3.2 Decoder Pre-Net (same as Tacotron 2)
The decoder pre-net in Transformer TTS transforms mel-spectrogram frames into a latent representation that aligns with the phoneme embedding space, allowing effective attention-based decoding.
It consists of:
- Two fully connected layers with 256 hidden units each
- ReLU activation after each layer
- Dropout for regularization
- Linear projection to match the scale and center of positional encodings
Why the Decoder Pre-Net Is Crucial
- Unlike the encoder, which receives symbolic phonemes, the decoder operates on real-valued mel-spectrogram frames.
- These mel frames are not learned embeddings and lie in a different space than the encoder’s phoneme representations.
- The decoder pre-net projects these frames into a compatible subspace, enabling attention alignment between the decoder queries and encoder keys/values.
Problem
Without the decoder pre-net, or if non-linearities are removed, attention fails to form reliable alignments, especially in early training.
Empirical Observations
- Removing ReLU layers or using a purely linear projection leads to poor or unstable attention.
- Increasing the hidden size to 512 showed no quality improvement but slower convergence.
- This suggests that mel spectrograms reside in a low-dimensional, compact subspace that is effectively captured by a 256-dim FC pipeline.
Final Projection and Positional Encoding
To ensure proper integration with positional encodings, the output of the decoder pre-net is re-centered using a final linear layer:
\[x_t = \text{Linear}(\text{ReLU}(\text{FC}_2(\text{FC}_1(\text{mel}_{t-1})))) + \alpha \cdot PE(t)\]This makes decoder inputs:
- Numerically compatible with sinusoidal PE
- Well-aligned with encoder outputs for stable attention
- Efficiently representational, enabling high-quality synthesis with fewer dimensions
4 Scaled Positional Encoding
Transformer TTS adapts the original sinusoidal positional encoding from Vaswani et al. (2017) to suit the TTS domain, where the encoder input (phoneme embeddings) and decoder input (mel spectrograms) belong to fundamentally different embedding spaces.
The positional encoding is defined as:
\[PE_{(pos, 2i)} = \sin\left(\frac{pos}{10000^{\frac{2i}{d_{\text{model}}}}}\right)\] \[PE_{(pos, 2i+1)} = \cos\left(\frac{pos}{10000^{\frac{2i}{d_{\text{model}}}}}\right)\]These encodings inject inductive bias about the relative and absolute order of sequence elements. However, directly adding them to learned embeddings (especially those from ReLU-activated CNNs) causes distribution mismatch since sinusoidal values are zero-centered, whereas ReLU outputs are non-negative.
To address this, Transformer TTS introduces a trainable scaling factor \( \alpha \) that modulates the strength of the positional encoding:
\[x_i = \text{prenet}(\text{phoneme}_i) + \alpha PE(i)\]This makes positional information adaptive to the modality-specific embedding distributions, whether it’s phoneme tokens (encoder) or mel spectrogram frames (decoder).
Ablation studies confirm that scaled positional encoding improves performance. Moreover, learned values of \( \alpha \) differed for encoder and decoder, reflecting the asymmetry between text and audio representations.
| Positional Encoding Type | MOS Score |
|---|---|
| Original (Fixed Scale) | 4.37 ± 0.05 |
| Scaled (Trainable \( \alpha \)) | 4.40 ± 0.05 |
5. Core Transformer Blocks
5.1 Encoder and Decoder Blocks:
Transformer TTS uses standard Transformer blocks.
Full Attention-Based Architecture: Replaces the RNNs and location-sensitive attention in Tacotron 2 with multi-head self-attention and dot-product attention, enabling global context modeling.
Parallelism in the Encoder: Unlike Tacotron 2’s recurrent encoder, Transformer TTS can process entire phoneme sequences in parallel, significantly reducing training time.
Better Long-Range Dependency Modeling: Self-attention connects any two positions directly, which is especially important for capturing sentence-level prosody and rhythm.
Simplified Attention Mechanism in the Decoder: Removes location-sensitive attention, reducing complexity and memory requirements, while still achieving accurate alignments via multi-head cross-attention. The paper did experiment with adding location-sensitivity to MHA, but it doubled memory and time cost, with minimal gain.
5.2 Transformer Encoder
Stacked blocks of:
- Multi-head self-attention: Each phoneme attends to all others in the sequence. This is critical for capturing sentence-level prosody and rhythm.
- Position-wise feed-forward layers
- Add & Norm residual connections
5.3 Transformer Decoder
Autoregressive decoder with:
- Masked multi-head self-attention
- Cross-attention over encoder outputs
- Feed-forward layers
- Positional encoding + residuals + normalization
6. Output Heads
6.1.1 Mel Linear (same as Tacotron 2)
- A linear projection layer that maps the decoder’s hidden state at each time step to a mel-spectrogram frame.
- This projection is trained using L1 or L2 loss against the ground truth mel-spectrogram. (same as Tacotron 2)
- It produces a coarse spectrogram, which the Post-Net further refines.
6.1.2 Stop Linear and Stop Token Prediction (same as Tacotron 2)
- A separate linear layer predicts whether the current frame is the final frame in the utterance.
- During training, a binary cross-entropy loss is applied:
1for the final frame0for all others
Problem: Class Imbalance
- There is only one positive label (stop = 1) per sequence but hundreds of negative labels (stop = 0).
- This imbalance leads to unstoppable inference where the model fails to terminate properly.
Solution: Weighted Loss
- The loss on the positive stop token is upweighted by a factor of 5.0–8.0 during training.
- This drastically improves stop prediction without harming mel quality.
6.1.3 Post-Net
- A 5-layer 1D CNN with residual connections and tanh activations.
- It outputs a residual correction that is added to the coarse mel-spectrogram from the Mel Linear layer.
- Purpose: refine spectrogram detail, especially in the high-frequency regions where coarse projections often blur.
Observations from the Paper
- The Post-Net plays a key role in producing natural-sounding speech, particularly with fine pitch and energy detail.
- Spectrograms from models without a Post-Net tend to be blurry and lack harmonic richness.
7. Experimental Results
| Model | MOS Score | CMOS vs Tacotron 2 |
|---|---|---|
| TransformerTTS | 4.39 ± 0.05 | +0.048 |
| Tacotron 2 | 4.39 ± 0.05 | baseline |
| Ground Truth | 4.44 ± 0.05 | — |
- Training time: ~4.25× faster than Tacotron 2
- Output quality: Comparable MOS, with improved spectrogram detail (especially in high-frequency regions)